
![]()
Guaranteed Success in Databricks Certification Databricks-Certified-Professional-Data-Engineer Exam Dumps
Databricks Databricks-Certified-Professional-Data-Engineer Daily Practice Exam New 2025 Updated 199 Questions
Databricks Certified Professional Data Engineer certification exam is a rigorous and comprehensive assessment of a candidate's knowledge and skills in data engineering. Databricks Certified Professional Data Engineer Exam certification provides a valuable credential for professionals seeking to demonstrate their expertise in designing and building data pipelines, managing data workflows, and implementing data analytics solutions using Databricks. With this certification, professionals can open up new career opportunities and demonstrate their commitment to excellence in the field of data engineering.
Databricks Certified Professional Data Engineer certification is a valuable credential for data engineers who work with the Databricks platform. It validates their skills and expertise and demonstrates to employers that they have the knowledge and experience needed to work with Databricks effectively. By passing the exam and earning the certification, data engineers can enhance their career prospects and gain a competitive advantage in the job market.
NEW QUESTION # 42
A data engineer wants to join a stream of advertisement impressions (when an ad was shown) with another stream of user clicks on advertisements to correlate when impression led to monitizable clicks.
Which solution would improve the performance?
- A.

- B.

- C.

- D.

Answer: A
Explanation:
When joining a stream of advertisement impressions with a stream of user clicks, you want to minimize the state that you need to maintain for the join. Option A suggests using a left outer join with the condition that clickTime == impressionTime, which is suitable for correlating events that occur at the exact same time.
However, in a real-world scenario, you would likely need some leeway to account for the delay between an impression and a possible click. It's important to design the join condition and the window of time considered to optimize performance while still capturing the relevant user interactions. In this case, having the watermark can help with state management and avoid state growing unbounded by discarding old state data that's unlikely to match with new data.
NEW QUESTION # 43
A dataset has been defined using Delta Live Tables and includes an expectations clause:
1. CONSTRAINT valid_timestamp EXPECT (timestamp > '2020-01-01')
What is the expected behaviour when a batch of data containing data that violates these constraints is
processed?
- A. Records that violate the expectation are added to the target dataset and recorded as invalid in the event log
- B. Records that violate the expectation are dropped from the target dataset and recorded as invalid in the event log
- C. Records that violate the expectation cause the job to fail
- D. Records that violate the expectation are added to the target dataset and flagged as in-valid in a field added to the target dataset
- E. Records that violate the expectation are dropped from the target dataset and loaded into a quarantine table
Answer: A
NEW QUESTION # 44
When building a DLT s pipeline you have two options to create a live tables, what is the main dif-ference between CREATE STREAMING LIVE TABLE vs CREATE LIVE TABLE?
- A. CREATE STREAMING LIVE TABLE is used when working with Streaming data sources and Incremental data
- B. CREATE LIVE TABLE is used in DELTA LIVE TABLES, CREATE STREAMING LIVE can only used in Structured Streaming applications
- C. CREATE STREAMING LIVE table is used in MULTI HOP Architecture
- D. CREATE LIVE TABLE is used when working with Streaming data sources and Incremental data
- E. There is no difference both are the same, CREATE STRAMING LIVE will be deprecated soon
Answer: A
Explanation:
Explanation
The answer is, CREATE STREAMING LIVE TABLE is used when working with Streaming data sources and Incremental data
NEW QUESTION # 45
Given the following error traceback:
AnalysisException: cannot resolve 'heartrateheartrateheartrate' given input columns:
[spark_catalog.database.table.device_id, spark_catalog.database.table.heartrate, spark_catalog.database.table.mrn, spark_catalog.database.table.time] The code snippet was:
display(df.select(3*"heartrate"))
Which statement describes the error being raised?
- A. There is a type error because a column object cannot be multiplied.
- B. There is a syntax error because the heartrate column is not correctly identified as a column.
- C. There is a type error because a DataFrame object cannot be multiplied.
- D. There is no column in the table named heartrateheartrateheartrate.
Answer: D
Explanation:
Comprehensive and Detailed Explanation From Exact Extract:
* Exact extract: "select() expects column names or Column expressions."
* Exact extract: "When using strings directly, Spark SQL interprets them as literal column names."
* Exact extract: "Python string operations, such as "colname"*3, return repeated strings, not column expressions." The expression 3*"heartrate" is Python string multiplication, which evaluates to "heartrateheartrateheartrate".
The select() method interprets this as a literal column name. Since there is no column with that name in the DataFrame schema, Spark raises AnalysisException saying it cannot resolve that column. To correctly multiply a column by a scalar, one must use the column expression form:
from pyspark.sql.functions import col
df.select((col("heartrate") * 3).alias("heartrate_x3"))
This ensures Spark evaluates the arithmetic operation on the column instead of misinterpreting the string.
References: PySpark DataFrame select; PySpark Column expressions with col().
NEW QUESTION # 46
To reduce storage and compute costs, the data engineering team has been tasked with curating a series of aggregate tables leveraged by business intelligence dashboards, customer-facing applications, production machine learning models, and ad hoc analytical queries.
The data engineering team has been made aware of new requirements from a customer-facing application, which is the only downstream workload they manage entirely. As a result, an aggregate table used by numerous teams across the organization will need to have a number of fields renamed, and additional fields will also be added.
Which of the solutions addresses the situation while minimally interrupting other teams in the organization without increasing the number of tables that need to be managed?
- A. Send all users notice that the schema for the table will be changing; include in the communication the logic necessary to revert the new table schema to match historic queries.
- B. Create a new table with the required schema and new fields and use Delta Lake's deep clone functionality to sync up changes committed to one table to the corresponding table.
- C. Add a table comment warning all users that the table schema and field names will be changing on a given date; overwrite the table in place to the specifications of the customer-facing application.
- D. Replace the current table definition with a logical view defined with the query logic currently writing the aggregate table; create a new table to power the customer-facing application.
- E. Configure a new table with all the requisite fields and new names and use this as the source for the customer-facing application; create a view that maintains the original data schema and table name by aliasing select fields from the new table.
Answer: E
Explanation:
This is the correct answer because it addresses the situation while minimally interrupting other teams in the organization without increasing the number of tables that need to be managed. The situation is that an aggregate table used by numerous teams across the organization will need to have a number of fields renamed, and additional fields will also be added, due to new requirements from a customer-facing application. By configuring a new table with all the requisite fields and new names and using this as the source for the customer-facing application, the data engineering team can meet the new requirements without affecting other teams that rely on the existing table schema and name. By creating a view that maintains the original data schema and table name by aliasing select fields from the new table, the data engineering team can also avoid duplicating data or creating additional tables that need to be managed. Verified References: [Databricks Certified Data Engineer Professional], under "Lakehouse" section; Databricks Documentation, under
"CREATE VIEW" section.
NEW QUESTION # 47
In order to use Unity catalog features, which of the following steps needs to be taken on man-aged/external tables in the Databricks workspace?
- A. Migrate/upgrade objects in workspace managed/external tables/view to unity catalog
- B. Copy data from workspace to unity catalog
- C. Upgrade workspace to Unity catalog
- D. Enable unity catalog feature in workspace settings
- E. Upgrade to DBR version 15.0
Answer: A
Explanation:
Explanation
Upgrade tables and views to Unity Catalog - Azure Databricks | Microsoft Docs Managed table: Upgrade a managed to Unity Catalog External table: Upgrade an external table to Unity Catalog
NEW QUESTION # 48
The data engineering team has configured a job to process customer requests to be forgotten (have their data deleted). All user data that needs to be deleted is stored in Delta Lake tables using default table settings.
The team has decided to process all deletions from the previous week as a batch job at 1am each Sunday. The total duration of this job is less than one hour. Every Monday at 3am, a batch job executes a series ofVACUUMcommands on all Delta Lake tables throughout the organization.
The compliance officer has recently learned about Delta Lake's time travel functionality. They are concerned that this might allow continued access to deleted data.
Assuming all delete logic is correctly implemented, which statement correctly addresses this concern?
- A. Because Delta Lake time travel provides full access to the entire history of a table, deleted records can always be recreated by users with full admin privileges.
- B. Because the default data retention threshold is 24 hours, data files containing deleted records will be retained until the vacuum job is run the following day.
- C. Because the default data retention threshold is 7 days, data files containing deleted records will be retained until the vacuum job is run 8 days later.
- D. Because the vacuum command permanently deletes all files containing deleted records, deleted records may be accessible with time travel for around 24 hours.
- E. Because Delta Lake's delete statements have ACID guarantees, deleted records will be permanently purged from all storage systems as soon as a delete job completes.
Answer: D
Explanation:
Explanation
This is the correct answer because Delta Lake's delete statements do not physically remove the data files that contain the deleted records, but only mark them as logically deleted in the transaction log. These files are still accessible with time travel until they are permanently deleted by the vacuum command. The default data retention threshold for vacuum is 7 days, but in this case it is overridden by setting it to 24 hours in each vacuum command. Therefore, deleted records may be accessible with time travel for around 24 hours after they are deleted, until they are vacuumed. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; [Databricks Documentation], under "Optimizations - Vacuum" section.
NEW QUESTION # 49
The data engineering team maintains a table of aggregate statistics through batch nightly updates. This includes total sales for the previous day alongside totals and averages for a variety of time periods including the 7 previous days, year-to-date, and quarter-to-date. This table is namedstore_saies_summaryand the schema is as follows:
The tabledaily_store_salescontains all the information needed to updatestore_sales_summary. The schema for this table is:
store_id INT, sales_date DATE, total_sales FLOAT
Ifdaily_store_salesis implemented as a Type 1 table and thetotal_salescolumn might be adjusted after manual data auditing, which approach is the safest to generate accurate reports in thestore_sales_summarytable?
- A. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and append new rows nightly to the store_sales_summary table.
- B. Implement the appropriate aggregate logic as a Structured Streaming read against the daily_store_sales table and use upsert logic to update results in the store_sales_summary table.
- C. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and use upsert logic to update results in the store_sales_summary table.
- D. Use Structured Streaming to subscribe to the change data feed for daily_store_sales and apply changes to the aggregates in the store_sales_summary table with each update.
- E. Implement the appropriate aggregate logic as a batch read against the daily_store_sales table and overwrite the store_sales_summary table with each Update.
Answer: D
Explanation:
The daily_store_sales table contains all the information needed to update store_sales_summary. The schema of the table is:
store_id INT, sales_date DATE, total_sales FLOAT
The daily_store_sales table is implemented as a Type 1 table, which means that old values are overwritten by new values and no history is maintained. The total_sales column might be adjusted after manual data auditing, which means that the data in the table may change over time.
The safest approach to generate accurate reports in the store_sales_summary table is to use Structured Streaming to subscribe to the change data feed for daily_store_sales and apply changes to the aggregates in the store_sales_summary table with each update. Structured Streaming is a scalable and fault-tolerant stream processing engine built on Spark SQL. Structured Streaming allows processing data streams as if they were tables or DataFrames, using familiar operations such as select, filter, groupBy, or join. Structured Streaming also supports output modes that specify how to write the results of a streaming query to a sink, such as append, update, or complete. Structured Streaming can handle both streaming and batch data sources in a unified manner.
The change data feed is a feature of Delta Lake that provides structured streaming sources that can subscribe to changes made to a Delta Lake table. The change data feed captures both data changes and schema changes as ordered events that can be processed by downstream applications or services. The change data feed can be configured with different options, such as starting from a specific version or timestamp, filtering by operation type or partition values, or excluding no-op changes.
By using Structured Streaming to subscribe to the change data feed for daily_store_sales, one can capture and process any changes made to the total_sales column due to manual data auditing. By applying these changes to the aggregates in the store_sales_summary table with each update, one can ensure that the reports are always consistent and accurate with the latest data. Verified References: [Databricks Certified Data Engineer Professional], under "Spark Core" section; Databricks Documentation, under "Structured Streaming" section; Databricks Documentation, under "Delta Change Data Feed" section.
NEW QUESTION # 50
An external object storage container has been mounted to the location /mnt/finance_eda_bucket.
The following logic was executed to create a database for the finance team:
After the database was successfully created and permissions configured, a member of the finance team runs the following code:
If all users on the finance team are members of the finance group, which statement describes how the tx_sales table will be created?
- A. A logical table will persist the query plan to the Hive Metastore in the Databricks control plane.
- B. An external table will be created in the storage container mounted to /mnt/finance eda bucket.
- C. An managed table will be created in the storage container mounted to /mnt/finance eda bucket.
- D. A managed table will be created in the DBFS root storage container.
- E. A logical table will persist the physical plan to the Hive Metastore in the Databricks control plane.
Answer: C
Explanation:
https://docs.databricks.com/en/lakehouse/data-objects.html
NEW QUESTION # 51
Which of the following statements describes Delta Lake?
- A. Delta Lake is an open format storage layer that delivers reliability, security, and per-formance
- B. Delta Lake is an open source platform to help manage the complete machine learning lifecycle
- C. Delta Lake is an open format storage layer that processes data
- D. Delta Lake is an open source data storage format for distributed data
- E. Delta Lake is an open source analytics engine used for big data workloads
Answer: A
Explanation:
Explanation
Delta Lake
NEW QUESTION # 52
Which is a key benefit of an end-to-end test?
- A. It makes it easier to automate your test suite
- B. It pinpoint errors in the building blocks of your application.
- C. It closely simulates real world usage of your application.
- D. It provides testing coverage for all code paths and branches.
Answer: C
Explanation:
End-to-end testing is a methodology used to test whether the flow of an application, from start to finish, behaves as expected. The key benefit of an end-to-end test is that it closely simulates real-world, user behavior, ensuring that the system as a whole operates correctly.
References:
* Software Testing: End-to-End Testing
NEW QUESTION # 53
A junior data engineer on your team has implemented the following code block.
The view new_events contains a batch of records with the same schema as the events Delta table. The event_id field serves as a unique key for this table.
When this query is executed, what will happen with new records that have the same event_id as an existing record?
- A. They are ignored.
- B. They are deleted.
- C. They are merged.
- D. They are inserted.
- E. They are updated.
Answer: A
Explanation:
This is the correct answer because it describes what will happen with new records that have the same event_id as an existing record when the query is executed. The query uses the INSERT INTO command to append new records from the view new_events to the table events. However, the INSERT INTO command does not check for duplicate values in the primary key column (event_id) and does not perform any update or delete operations on existing records. Therefore, if there are new records that have the same event_id as an existing record, they will be ignored and not inserted into the table events. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Append data using INSERT INTO" section.
"If none of the WHEN MATCHED conditions evaluate to true for a source and target row pair that matches the merge_condition, then the target row is left unchanged."
https://docs.databricks.com/en/sql/language-manual/delta-merge-into.html#:~:text=If%20none%20of%20the%20
NEW QUESTION # 54
A query is taking too long to run. After investigating the Spark UI, the data engineer discovered a significant amount of disk spill. The compute instance being used has a core-to-memory ratio of 1:2.
What are the two steps the data engineer should take to minimize spillage? (Choose 2 answers)
- A. Choose a compute instance with a higher core-to-memory ratio.
- B. Choose a compute instance with more network bandwidth.
- C. Increase spark.sql.files.maxPartitionBytes.
- D. Choose a compute instance with more disk space.
- E. Reduce spark.sql.files.maxPartitionBytes.
Answer: A,E
Explanation:
Comprehensive and Detailed Explanation From Exact Extract of Databricks Data Engineer Documents:
Databricks recommends addressing disk spilling-which occurs when Spark tasks run out of memory-by increasing memory per core and controlling partition size. Selecting an instance type with a higher memory-to-core ratio (A) provides each task with more available RAM, directly reducing the chance of spilling to disk. Additionally, reducing spark.sql.files.maxPartitionBytes (D) creates smaller partitions, preventing any single task from holding too much data in memory. Increasing partition size (C) or disk capacity (B) does not solve memory bottlenecks, and bandwidth (E) affects network I/O, not spill behavior. Therefore, the correct actions are A and D.
NEW QUESTION # 55
A Delta Lake table was created with the below query:
Realizing that the original query had a typographical error, the below code was executed:
ALTER TABLE prod.sales_by_stor RENAME TO prod.sales_by_store
Which result will occur after running the second command?
- A. A new Delta transaction log Is created for the renamed table.
- B. The table reference in the metastore is updated and no data is changed.
- C. All related files and metadata are dropped and recreated in a single ACID transaction.
- D. The table name change is recorded in the Delta transaction log.
- E. The table reference in the metastore is updated and all data files are moved.
Answer: B
Explanation:
The query uses the CREATE TABLE USING DELTA syntax to create a Delta Lake table from an existing Parquet file stored in DBFS. The query also uses the LOCATION keyword to specify the path to the Parquet file as /mnt/finance_eda_bucket/tx_sales.parquet. By using the LOCATION keyword, the query creates an external table, which is a table that is stored outside of the default warehouse directory and whose metadata is not managed by Databricks. An external table can be created from an existing directory in a cloud storage system, such as DBFS or S3, that contains data files in a supported format, such as Parquet or CSV.
The result that will occur after running the second command is that the table reference in the metastore is updated and no data is changed. The metastore is a service that stores metadata about tables, such as their schema, location, properties, and partitions. The metastore allows users to access tables using SQL commands or Spark APIs without knowing their physical location or format. When renaming an external table using the ALTER TABLE RENAME TO command, only the table reference in the metastore is updated with the new name; no data files or directories are moved or changed in the storage system. The table will still point to the same location and use the same format as before. However, if renaming a managed table, which is a table whose metadata and data are both managed by Databricks, both the table reference in the metastore and the data files in the default warehouse directory are moved and renamed accordingly. Verified Reference: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "ALTER TABLE RENAME TO" section; Databricks Documentation, under "Metastore" section; Databricks Documentation, under "Managed and external tables" section.
NEW QUESTION # 56
You are currently working on a production job failure with a job set up in job clusters due to a data issue, what cluster do you need to start to investigate and analyze the data?
- A. Existing job cluster can be used to investigate the issue
- B. A Job cluster can be used to analyze the problem
- C. All-purpose cluster/ interactive cluster is the recommended way to run commands and view the data.
- D. Databricks SQL Endpoint can be used to investigate the issue
Answer: C
Explanation:
Explanation
Answer is All-purpose cluster/ interactive cluster is the recommended way to run commands and view the data.
A job cluster can not provide a way for a user to interact with a notebook once the job is submitted, but an Interactive cluster allows to you display data, view visualizations write or edit quries, which makes it a perfect fit to investigate and analyze the data.
NEW QUESTION # 57
Which of the following technologies can be used to identify key areas of text when parsing Spark Driver log4j output?
- A. Scala Datasets
- B. C++
- C. Regex
- D. Julia
- E. pyspsark.ml.feature
Answer: C
Explanation:
Regex, or regular expressions, are a powerful way of matching patterns in text. They can be used to identify key areas of text when parsing Spark Driver log4j output, such as the log level, the timestamp, the thread name, the class name, the method name, and the message. Regex can be applied in various languages and frameworks, such as Scala, Python, Java, Spark SQL, and Databricks notebooks. References:
* https://docs.databricks.com/notebooks/notebooks-use.html#use-regular-expressions
* https://docs.databricks.com/spark/latest/spark-sql/udf-scala.html#using-regular-expressions-in-udfs
* https://docs.databricks.com/spark/latest/sparkr/functions/regexp_extract.html
* https://docs.databricks.com/spark/latest/sparkr/functions/regexp_replace.html
NEW QUESTION # 58
A Databricks SQL dashboard has been configured to monitor the total number of records present in a collection of Delta Lake tables using the following query pattern:
SELECT COUNT (*) FROM table -
Which of the following describes how results are generated each time the dashboard is updated?
- A. The total count of rows will be returned from cached results unless REFRESH is run
- B. The total count of records is calculated from the parquet file metadata
- C. The total count of rows is calculated by scanning all data files
- D. The total count of records is calculated from the Delta transaction logs
- E. The total count of records is calculated from the Hive metastore
Answer: D
Explanation:
https://delta.io/blog/2023-04-19-faster-aggregations-metadata/#:~:text=You%20can%20get%20the%
20number,a%20given%20Delta%20table%20version.
NEW QUESTION # 59
A nightly job ingests data into a Delta Lake table using the following code: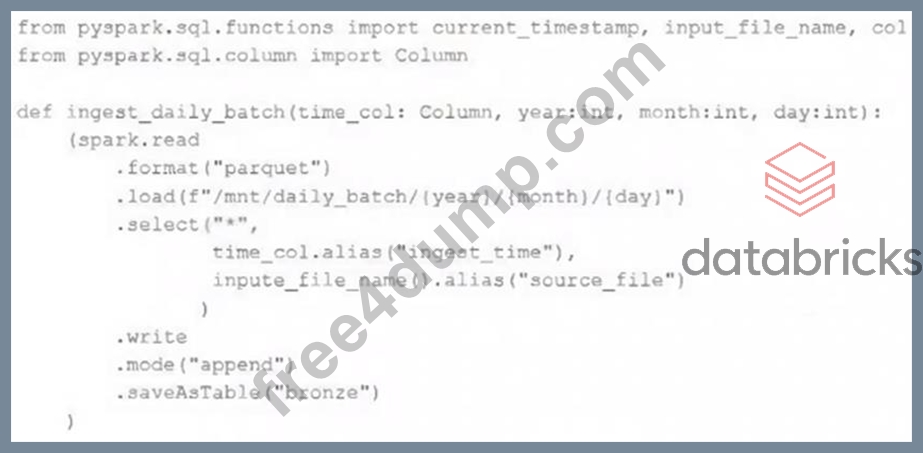
The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
def new_records():
A . return spark.readStream.table("bronze")
B . return spark.readStream.load("bronze")
C .
D .
return spark.read.option("readChangeFeed", "true").table ("bronze")
E .
- A. Option D
- B. Option E
- C. Option C
- D. Option A
- E. Option B
Answer: B
Explanation:
https://docs.databricks.com/en/delta/delta-change-data-feed.html
NEW QUESTION # 60
Which of the following python statement can be used to replace the schema name and table name in the query statement?
- A. 1.table_name = "sales"
2.schema_name = "bronze"
3.query = f"select * from { schema_name}.{table_name}" - B. 1.table_name = "sales"
2.schema_name = "bronze"
3.query = f"select * from + schema_name +"."+table_name" - C. 1.table_name = "sales"
2.schema_name = "bronze"
3.query = f"select * from schema_name.table_name" - D. 1.table_name = "sales"
2.schema_name = "bronze"
3.query = "select * from {schema_name}.{table_name}"
Answer: A
Explanation:
Explanation
Answer is
table_name = "sales"
query = f"select * from {schema_name}.{table_name}"
f strings can be used to format a string. f" This is string {python variable}"
https://realpython.com/python-f-strings/
NEW QUESTION # 61
A newly joined team member John Smith in the Marketing team currently has access read access to sales tables but does not have access to update the table, which of the following commands help you accomplish this?
- A. GRANT UPDATE TO TABLE table_name ON [email protected]
- B. GRANT USAGE ON TABLE table_name TO [email protected]
- C. GRANT UPDATE ON TABLE table_name TO [email protected]
- D. GRANT MODIFY TO TABLE table_name ON [email protected]
- E. GRANT MODIFY ON TABLE table_name TO [email protected]
Answer: E
Explanation:
Explanation
The answer is GRANT MODIFY ON TABLE table_name TO [email protected]
https://docs.microsoft.com/en-us/azure/databricks/security/access-control/table-acls/object-privileges#privileges
NEW QUESTION # 62
......
The DCPDE certification is an excellent way for data professionals to demonstrate their expertise in the Databricks platform. Databricks Certified Professional Data Engineer Exam certification is recognized globally and is highly valued by employers looking for data professionals with expertise in Databricks. The DCPDE certification provides professionals with the opportunity to enhance their career prospects and increase their earning potential.
Test Engine to Practice Databricks-Certified-Professional-Data-Engineer Test Questions: https://passleader.free4dump.com/Databricks-Certified-Professional-Data-Engineer-real-dump.html